Creative agents that make you prolific
Type a prompt below. See what’s possible.
Luma Announces Open Physical AI Lab to Solve Generalization in Physical AI
Learn moreOur Mission is to build unified general intelligence that can generate, understand, and operate in the physical world.
Force multiplying teams at





Product & Platform
Foundations for a new era of creativity and human expression.
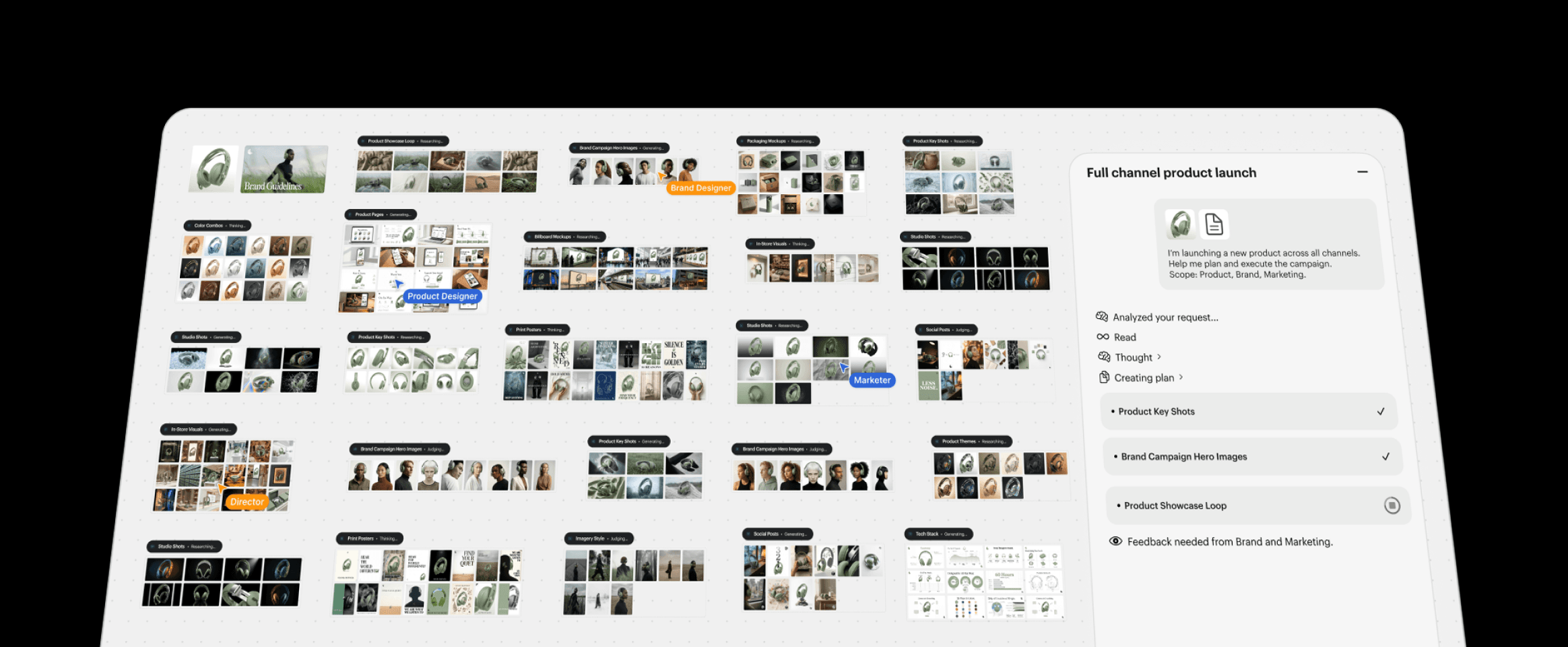
Luma
Direct creative work from concept to delivery with agents that generate, transform, and coordinate media across image, video, and audio, and text.
Research
We are focused on foundational research and systems engineering to build multimodal general intelligence.

The Open Physical AI Lab
An open science effort to solve generalization in physical AI, built in the open for the benefit of all humanity.

UNI-1
Uni-1, Luma’s first unified understanding and generation model, is our next step on the path towards multimodal general intelligence.
RAY3.14
A new generation of video model capable of producing fast coherent motion, ultra-realistic details, and logical event sequences.

Pushing the Limit of Efficient Inference-Time Scaling with Terminal Velocity Matching

Ray3 Evaluation Report – State-of-the-Art Performance for Pro Video Generation

Breaking the Algorithmic Ceiling in Pre-Training with Inductive Moment Matching
Recent News
Stay up to date with the latest from Luma AI — company updates, model releases, and stories from across the industry.




Team & Community
Everything we can imagine should be real.
Careers
We're a lean, high-achieving team in Palo Alto building the future of creative intelligence. If you share our vision of AI that transcends current boundaries to enable extraordinary human expression, we'd love to talk.
Learning Center
Explore what you can create with Luma. Discover workflows, best practices, and new ways to bring ideas to life with an intelligent multimodal Agent by your side.