Make it with Dream Machine
Production-ready images and videos with precision, speed, and control
Our Mission is to build multimodal general intelligence that can generate, understand, and operate in the physical world.
Product & Platform
Foundations for a new era of creativity and human expression.
Dream Machine
Ideate, visualize, and create videos using our most powerful image and video models. Available now on iOS and the Web.
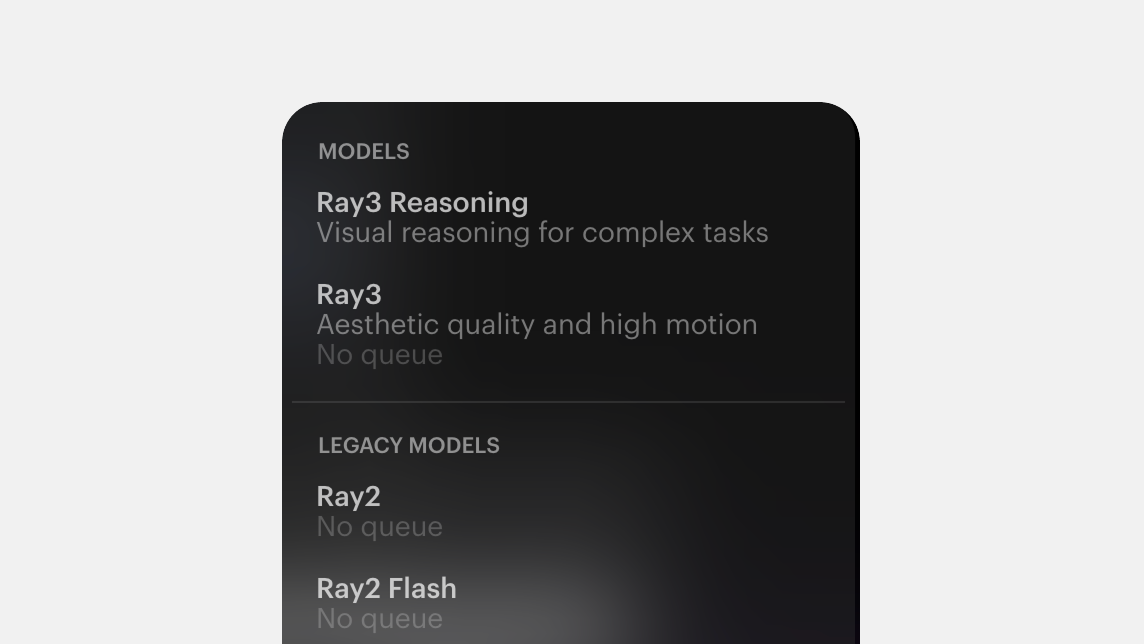
Models
State-of-the-art multimodal models that power Dream Machine and enable high-fidelity image and video.
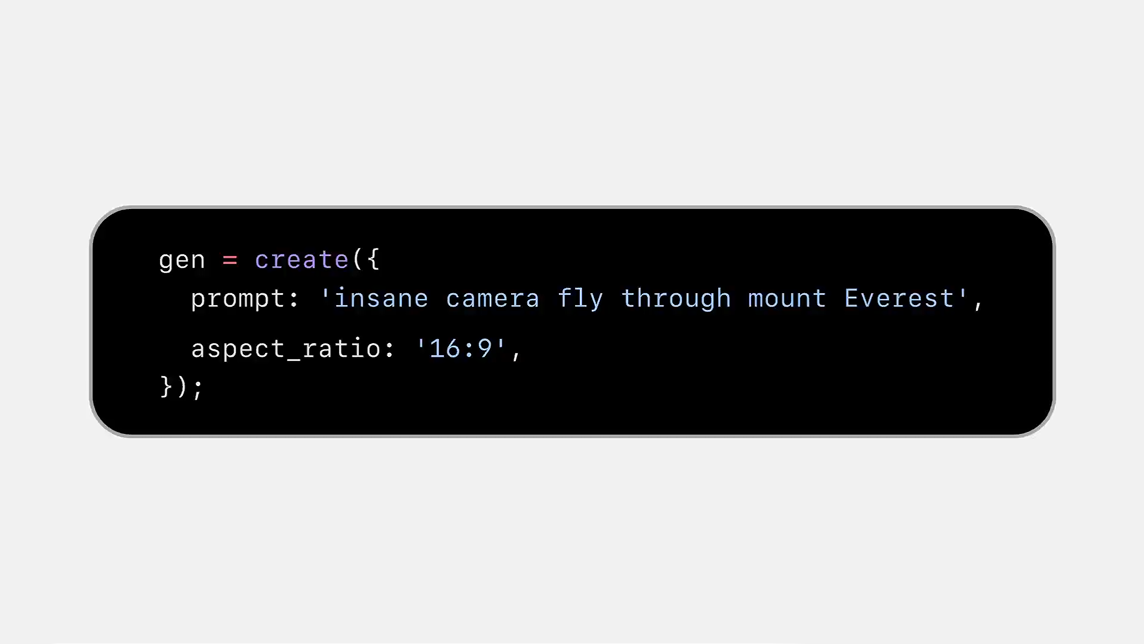
Luma AI API
Build and scale creative products with high-quality video and image generation models through the Luma API.
Recent News
Stay up to date with the latest from Luma AI — company updates, model releases, and stories from across the industry.




Research
We are focused on foundational research and systems engineering to build multimodal general intelligence.
A new generation of video model capable of producing fast coherent motion, ultra-realistic details, and logical event sequences.
Creative, intelligent and personalizable image generation model that delivers ultra high quality and 10x higher cost efficiency.
Pushing the Limit of Efficient Inference-Time Scaling with Terminal Velocity Matching
November 26, 2025Linqi Zhou, Ayaan Haque
Ray3 Evaluation Report – State-of-the-Art Performance for Pro Video Generation
October 14, 2025Sabrina Day, Simran Motwani
Team & Community
Everything we can imagine should be real.

We're a small, high-achieving team building multimodal general intelligence If you share our vision of AI that transcends current boundaries to enable extraordinary capabilities and human-AI collaboration, we'd love to talk.

Explore the possibilities unlocked through world building. Find tutorials, best practices, and inspiring examples from our community of millions of creatives. Learn how others are using Dream Machine, and the Luma API to transform their creative process across design, film, education, and beyond.